Honest charts: Ethics and integrity in data visualisation
As data becomes more and more important in all aspects of our daily lives, the importance of clear, accurate, but also ethical and trustworthy data visualisation is undeniable. Visuals can clarify complex topics but can also mislead if not handled responsibly. In this conversation, we explore this critically important topic with Xaquín G. V., a seasoned visual journalist and data visualisation expert. Xaquín has contributed to various publications and trained professionals on ethical storytelling through data. Moreover, he addressed this very topic in his presentation at the EU DataViz 2019 conference. Here, he shares his insights on how visualisations can be manipulated and how to address such issues.
Q: Xaquín, some people might think that as long as a data visualisation uses accurate data it cannot be misleading. What are your thoughts on that?
A: Earlier this year, the X algorithm served me this gem.
Figure 1: A tweet by "Rep. Jack Kimble"
New data shows this has not improved since last year. If anything it’s stayed exactly the same. We need to seek solutions and some people might not like it, but we have to do something. https://t.co/9qBL40FdUD
— Rep. Jack Kimble (@RepJackKimble) May 14, 2024
The absurdity of the claim made it clear to me, a data professional, that this had to be a joke. Yet, the tweet’s replies revealed that not everyone caught on. (Jack Kimble is a political parody, a fictitious representative of California’s non-existent 54th congressional district.)
The brilliance of the account’s humour is that it wasn’t entirely unplausible to see a public figure doubling down on his misunderstanding of statistics.
What made it even wittier – to me – was that the statement was backed by a powerful supporting component, a supposedly indisputable element that grounded this assertion in truth: a chart!
If words can be twisted, visuals can be too. We might be tempted to assume that just because you need data to create them, data visualisations are harder to mislead with or misinterpret. But data visualisations can be misleading, sometimes by accident, other times by design.
The entire data visualisation process – from collecting and filtering the data to deciding how to present it – carries opportunities for misrepresentation. It’s rarely just about the chart itself but the decisions made long before it reaches the viewer. What data is included? What’s left out? How are comparisons framed? Are the bits that pop the most – the prominent peaks and valleys of a line chart or the ‘hotter’ areas in a map – explained or contextualised? Was the chart meant to be shown by itself? If any of these steps lack transparency or care, the result can confuse or deceive.
Figure 2: Diagram of the data visualisation cycle; from data collection and analysis to visualisation and communication (source: the author)
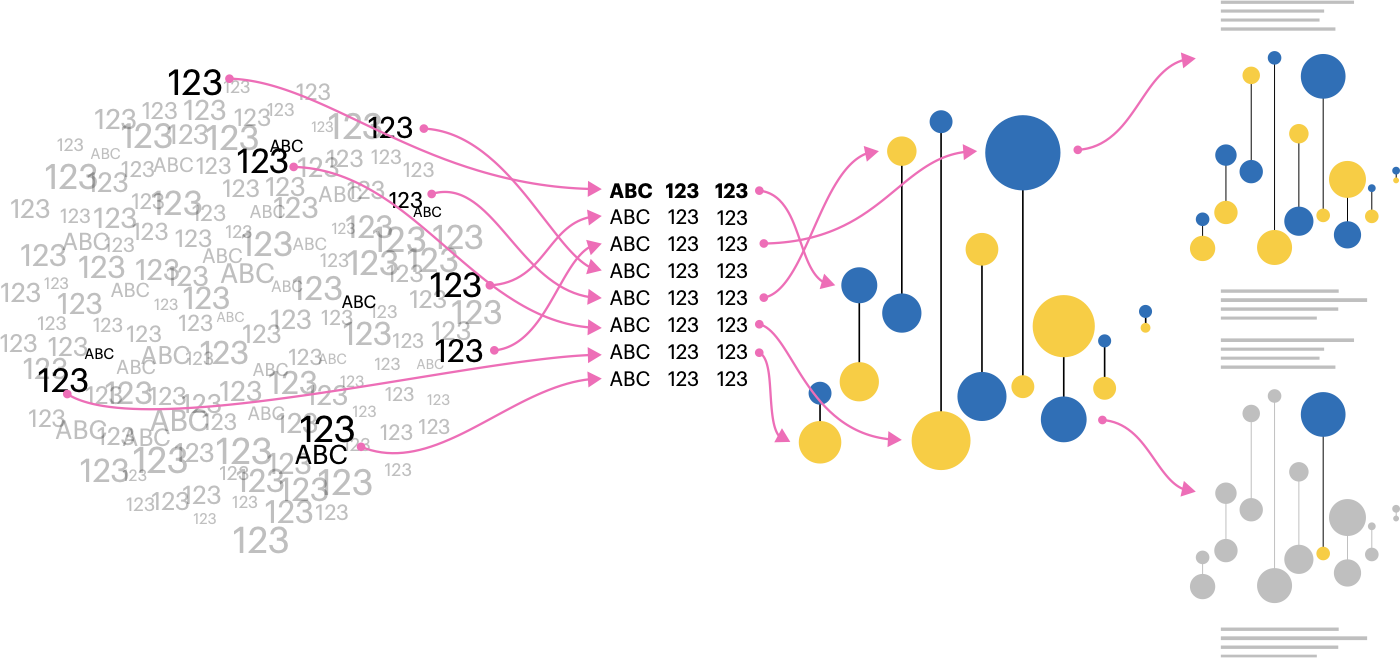
Q: For creators and audiences of data visualisations alike, could you provide a framework for identifying areas where things might go or be wrong?
A: Let’s break it down by exploring where things can go wrong: with the data, with the visualisation and with the context.
[NB: Headings have been added to the interview answers for organisational purposes]
Something’s up with the data
Data visualisations are only as honest as the data behind them. If the data is flawed, incomplete or misrepresented, whatever you do down the line will be too.
Sometimes it happens simply due to the communicator’s lack of data literacy, like when someone cherry-picks data points that prove their point or worse, uses data from an unrelated dataset.
Sometimes, even more problematically, it happens when someone misuses data analysis techniques to fit their hypothesis when the data doesn’t support the narrative they’re trying to tell – something called data dredging. The proverb that ‘if you torture data long enough, it will confess to anything’ – widely attributed to British Nobel Prize-winning economist Ronald H. Coase – sums it up neatly.
And sometimes, in an era where press releases double as news and many organisations publish ‘research’ that isn’t peer-reviewed or critically analysed, it happens when journalists end up using such data because it’s readily available and well-packaged. This wave of P.R. data, as Jacob Harris puts it, can flood the information space with biased narratives disguised as facts. What’s tricky is that while the data itself may not be inherently false, it is often selected and framed to push a specific agenda, leaving out key details that would lead to a more nuanced, or even opposite, conclusion.
But even if we have the correct data for our hypothesis, we might be framing it misleadingly. One of my favourite examples has to do with time series: where do we start and where, or rather when, do we cut the series off, what do we do with the variance – how much do the values deviate from the mean, or with the seasonality – if the phenomenon the data is measuring is tied to regular cycles?
Take this air pollution dataset, a time series of 20 years of hourly levels of coarse particulate matter – also known as PM10 – from a weather station in the heart of Barcelona city.
Figure 3: Time series of air pollution data from Barcelona (source: Air quality at the automatic measurement points of the Monitoring and Forecasting Network of Atmospheric Pollution).
I came up with three different trends and stories in the shape of an acute (´), a circumflex (^), and a grave (`) accent mark. Do you see when each of the trends peaks: at the beginning, middle, and end? All three visualisations come from the same dataset but show three wildly different patterns just by massaging the beginning and end of the series and the granularity of the data – showing monthly or yearly averages.
You can play with the interactive graph to create even more trends and stories.
Figure 4: An interactive graph related to the previous air pollution data
What can we do?
- Share your sources and datasets in formats that other data people can reuse.
- Document your methodology, including any data transformations or cleaning, so that others can reproduce your findings.
- Make the scope and limitations of your data clear, noting missing data, biases or any assumptions that may affect interpretation.
- Disclose how data was collected, processed and filtered to provide context and reduce the risk of it being misapplied.
- Essentially, be transparent. Transparency equals trust.
Something’s up with the visualisation
Even when the data and analysis are sound and transparent, the way it’s visualised can affect its interpretation.
Like data analysis, visualisation is an active step where every decision – from chart type to colour scheme – affects the message. Choosing the ‘right chart’ – a word pair that I particularly dislike – is about revealing to viewers the hidden patterns in the data, about enabling them to see the groupings, the trends, the comparisons, etc.
It’s about finding a visual format for the answer to a data question and avoiding unnecessary visual complexity that could obscure the message or mislead the viewer.
I can already hear the ‘Fine! Ugh! Let’s make everything a bar chart then!’ But as my colleague Amanda Cox once put it: ‘There’s a strand of the data viz world that argues that everything could be a bar chart. That’s possibly true but also possibly a world without joy.’ That’s far from our intention here.
Imagine that you’ve got a dataset containing the percentage of people per region that might be exposed to windstorms, coastal flooding, river flooding, water shortage or wildfire danger in 2050 under a 2 °C global warming scenario.
Now imagine the absurdity of stacking more than one thousand bars – one per region …
Figure 5: Stacking over a thousand bars to show regional percentages of people exposed to various climate risks by 2050 under a 2°C warming scenario
… when the most significant pattern that the data reveals is a geographical one: that real trouble begins south of the 42nd parallel north.
Figure 6: An alternative approach to visualise regional percentages of people exposed to various climate risks by 2050 under a 2°C warming scenario (source: ‘Human exposure to harmful climate impacts’ map from the Joint Research Centre via the Ninth Report on Economic, Social and Territorial Cohesion.
One version obscures, the other one illuminates.
Every chart has its strengths. And every chart has its limitations. A pie chart breaks down if the slices are too similar or if there are too many. A multiline chart with too many categories looks like a multicoloured knitted sweater. Scatterplots aren’t really meant for categorical data. A map is no help when the interesting patterns aren’t geographic patterns.
But there are many other ways something can be up with the visualisation. Even with a chart type that amplifies the relationships in the data, a distorted axis, dubious colour choices or missing labels or annotations can hinder your message.
A distorted axis can make minor changes look dramatic or hide significant shifts. The classic truncated y-axis at a value higher than zero in a bar chart exaggerates the difference between two data points, and compressing the x-axis on a time-series graph can make rapid changes appear gradual.
An unusual axis orientation must be accompanied by clear annotations or design elements that reinforce the switch, or it will be most definitely misread. The example below is inspired by a misguided chart about ‘Gun deaths in Florida’ – itself misguidedly inspired by an impactful chart of ‘Iraq’s bloody toll’.
Figure 7: Alternative visualisations of EU greenhouse gas emissions (Data source: ‘Greenhouse emissions in the EU’, Eurostat)
Colour can clarify or create confusion. A heat map that uses dark colours for low values and light colours for high values might confuse readers who reasonably associate darker colours with larger numbers.
Toying with intuitive colour associations can have its drawbacks, like in this mind-bending choice of blue for land areas and ochre for marine areas.
Figure 8: Land and marine protected areas in the EU (Data source: ‘Surface of the terrestrial protected areas’ and ‘Surface of the marine protected areas’, Eurostat)
And few things distinguish good and great visualisations better than a proper annotation layer. Annotations are crucial for understanding what’s behind the patterns that have been revealed, and when they are missing or unclear, the viewer is left to make assumptions. Key details such as data sources, units of measurement or time frames must be clearly labelled. Even a well-designed visualisation can be easily misinterpreted when the reader isn’t familiar with the topic or the visualisation is shared widely outside its intended context, and good annotation is a safeguard against this.
What can we do?
- Test out different visualisations to understand which type makes the data patterns more comprehensible and conveys the message more clearly.
- Avoid flourishes that can distort how your audience understands the data: eye-catching visuals are great, but accurate insights are more important.
- Ensure that you design for everyone, including those with poor connectivity, reduced mobility, vision deficiencies, limited data literacy, etc.
- Label the elements that guarantee your audience can decode your visualisation, your axes, scales and units, etc.
- Annotate key data points, trends or outliers directly within the chart to help people interpret it and to reduce ambiguity.
Something’s up with the context
Even with the ‘right’ data and visualisation, the context in which a graphic is presented can skew viewer interpretation.
In September 2019, at the dawn of the first impeachment proceedings against Donald Trump, we saw the latest misinterpretation of what choropleth [maps] can and cannot do, as social media users widely shared a map of the 2016 election results under the tagline ‘Try to impeach this.’
The map was binary: in red were the counties won by Mr Trump and in blue were the counties won by Hillary Clinton. It showed that, and only that. It’s not a map of popular support – ‘acres don’t vote, people do’ – or approval. Data visualisation specialists were quick to point that out. I’ve always been very open about how I feel about election choropleth [maps] and my fondness for alternative views.
Figure 9: A map of the 2016 US election results, widely shared by social media users
Challenge accepted! Here is a transition between surface area of US counties and their associated population. This arguably provides a much more accurate reading of the situation. @observablehq notebook: https://t.co/wdfMeV5hO4 #HowChartsLie #DataViz #d3js https://t.co/lStHeeuMUw pic.twitter.com/MpYiXtsHmu
— Karim Douïeb (@karim_douieb) October 8, 2019
As the always insightful Alberto Cairo says in How Charts Lie: ‘A chart shows only what it shows, and nothing else.’
In July 2020, we heard the nth accusation of data wrongdoing by the Georgia Department of Public Health when an X user posted, side by side, two maps from their COVID-19 dashboard from two different days. The maps’ colour scale had shades of blue throughout except for the last bin – the last step –which was red, meant to highlight the largest outbreaks of that day. According to the critique, the trouble was that the same shade of blue meant wholly different figures on each map.
Well … the authors of this dashboard never intended for you to collate them into two maps!
We had a very similar issue here in Europe in April 2021 that led two media outlets to exchange allegations of manipulation. Bild accused Tagesschau of misleading the public with its colour-coded COVID-19 maps when X users showed two different days side by side with two different colour scales. The claim was that Tagesschau had used darker shades of red to make the infection rates appear more alarming than before. Tagesschau responded by explaining that the new colour scheme was based on a revised threshold for critical infection levels, in line with updated public health guidelines.
(I’ve refrained from modifying the colours in the scale and have kept them as close as possible to the original, despite my inner designer shouting to tweak the palette.)
Figure 10: Visualisations of the seven-day COVID-19 incidence in Germany at two different times, illustrating the impact of differing color scales (Source: ‘COVID-19 case numbers for Germany’)
It was the Georgia Department of Public Health debacle all over again.
Yes, you can question the thresholds they used to assign a colour to each district and the uneven hue and saturation of the scale. But those maps were never meant to appear next to each other. It’s more the interpreter – and their intent – who’s at fault here, and not so much the author.
Tagesschau admitted some fault: while both graphics appeared on their Instagram channel, one was from their television report and the other from their digital platform. They agreed that using different graphics across media platforms caused confusion but emphasised that there was no intent to manipulate the data.
Below are both maps with the same colour scale, just for reference and to keep the peace.
Figure 11: Visualizations of the seven-day COVID-19 incidence in Germany at two different times, with standardised color scales
What can we do?
- Provide enough context about the data, including time frames, geographic scope and relevant variables, to avoid out-of-context interpretation.
- Present data alongside comparable metrics or historical benchmarks so the audience understands where your snapshot fits within the broader trend.
- Disclose the intent of the visualisation, whether it’s to inform, persuade or explore, so the audience is in the right mindset to approach it.
- Be transparent about any changes, updates, adjustments, erratum, etc., especially about long-term issues that may require you to adapt the visuals.
Over 110 years ago, in this gem of a book called Graphic Methods for Presenting Facts, an American engineer called Willard C. Brinton wrote: ‘If an editor should print bad English, he would lose his position. Many editors are using and printing bad methods of graphic presentation, but they hold their jobs just the same.’ That’s a bit of an extreme statement. Plenty of editors – whether in print or digital media – publish bad English and even misleading facts and yet ‘hold their jobs just the same.’ But the quote and Brinton’s concerns remain as relevant as ever and speak to the age of our modern worries about honesty, integrity and ethics in data visualisation.
Closing thoughts
At a time when crafting visually stunning graphics is easier than ever and social media encourages increasingly shorter attention spans, the risk of deception and misinterpretation grows. Just like words, charts can clarify or confuse. Misleading visuals can skew public understanding and erode trust. And while a poorly written sentence might spark debate, a poorly designed chart can change opinions or policy. Hopefully, better guidelines, more aware professionals, more transparency and data literacy efforts can help us do better.
Visualising data is more than transforming numbers into charts; it’s about conveying reality with accuracy and responsibility. We hope that, with the guidance provided in this data story, you are now better equipped to approach data visualisations with a critical eye, whether you’re creating or interpreting them. At data.europa.eu, we are committed to fostering transparency, promoting data literacy and supporting ethical standards in data visualisation to help build trust and ensure data serves the public good.
Assets
Geography for the maps:
Check out all the data transformations in the Observable notebook.
References
Berinato, S., ‘The power of visualization’s “Aha!” moments’, Harvard Business Review, 19 March 2013, accessed 24 September 2024, https://hbr.org/2013/03/power-of-visualizations-aha-moment.
Bild, ‘Heftige Zuschauerkritik nach neuen Farben: Warum malt die Tagesschau die Corona-Karte so düster?’, 11 April 2021, accessed 25 September 2024, https://www.bild.de/politik/inland/politik-inland/heftige-zuschauerkritik-nach-neuen-farben-warum-malt-die-tagesschau-die-corona-k-76026922.bild.html.
Bresciani, S. and Eppler, M. J., ‘The pitfalls of visual representations: A review and classification of common errors made while designing and interpreting visualizations’, Sage Open, Vol. 5, No 4, 14 October 2015, accessed 30 September 2024, https://doi.org/10.1177/2158244015611451.
Brinton, W. C., Graphic Methods for Presenting Facts, The Engineering Magazine Company, New York, 1914, https://archive.org/details/graphicmethodsfo00brinrich.
Cairo, A., How Charts Lie: Getting Smarter About Visual Information, W. W. Norton & Company, 15 October 2019, https://wwnorton.com/books/9781324001560.
Chen, C., ‘Gun deaths in Florida: Number of murders committed using firearms’, Reuters, 18 February 2014, accessed 2 October 2024, https://vizhub.com/sjengle/5a7cf326924944d8971a5f8b93a8166d.
Ericson, M., ‘When maps shouldn’t be maps’, 14 October 2011, accessed 24 September 2024, https://www.ericson.net/content/2011/10/when-maps-shouldnt-be-maps/.
Harris, J., ‘A wave of P.R. data’, Nieman Lab, 2014, accessed 20 September 2024, https://www.niemanlab.org/2014/12/a-wave-of-p-r-data/.
Scarr, S., ‘Iraq’s bloody Toll’, South China Morning Post, 2011, accessed 2 October 2024, https://www.simonscarr.com/iraqs-bloody-toll.
Schwabish, J., ‘Critiquing a data visualization critique’, PolicyViz, 19 July 2020, accessed 27 September 2024, https://policyviz.com/2020/07/19/critiquing-a-data-visualization-critique/.
Tagesschau, ‘Faktenfinder: Keine Manipulation bei Corona-Karten’, 13 April 2021, accessed 25 September 2024, https://www.tagesschau.de/faktenfinder/tagesschau-corona-karten-101.html.