Linking data: EU vocabularies
The benefits of using linked open reference data
In our new ‘Linking data’ series, we are presenting EU projects that use linked open data (LOD). What data is linked in these projects? Why did they decide to use LOD? What benefits does it bring? Follow the series to find out.
In this episode, we focus on EU reference data. Read on to find out what it is and how and why it uses LOD.
What is reference data?
To start, we will introduce you to some important concepts.
-
Reference data
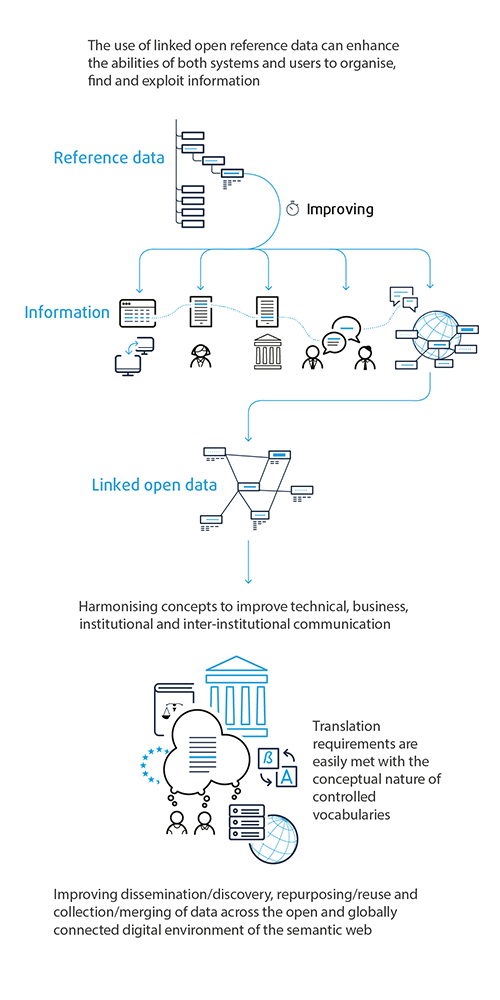
In simple terms, reference data is data used to classify or categorise other data. A reference data vocabulary defines the values allowed to be used in a specific field, such as currency, country codes or units of measurement.
Reference data vocabularies are the fundamental building blocks of most information systems. While they can be defined and managed internally, many reference data assets are maintained by standards organisations (e.g. International Organization for Standardization), public institutions or industry consortia.
Such standardised vocabularies have many advantages.
-
They play a key role in improving communication, data sharing and integration.
-
They increase the potential to organise, find and exploit information by both systems and users.
-
They are crucial for data linking, as publishing linked data relies on using vocabularies that can be connected and interpreted by machines.
-
EU reference data
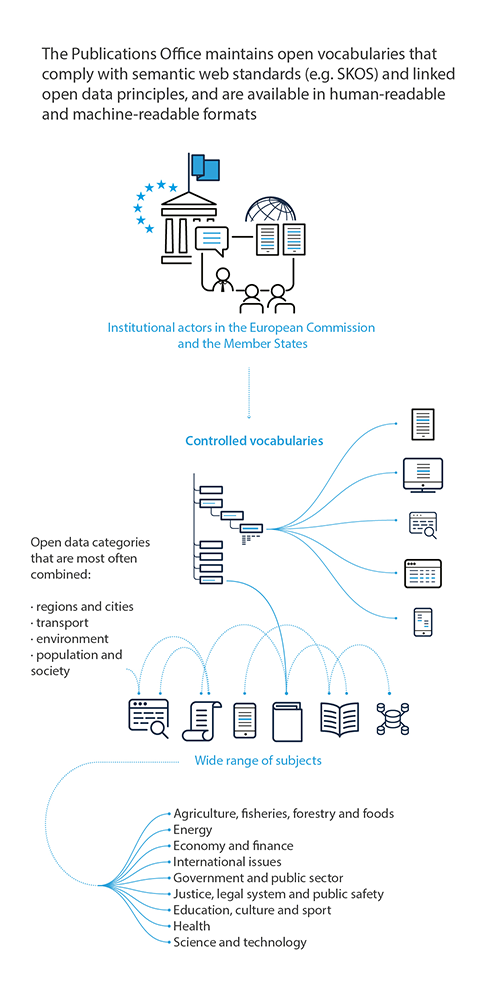
The EU reference data catalogue, maintained by the Publications Office of the European Union, offers access to multiple controlled vocabularies, data models and collections of semantic assets linked to specific projects.
The vocabularies are constructed on top of recognised standards (e.g. Simple Knowledge Organization System) and cover a wide range of subjects. They are available in machine-readable formats, both as downloadable resources and through standardised interfaces that support development of smarter software platforms. The EU Vocabularies website also offers functions to make the vocabularies’ content accessible for direct human usage.
All of these vocabularies are available in the 24 official EU languages.
-
Controlled vocabularies and data models
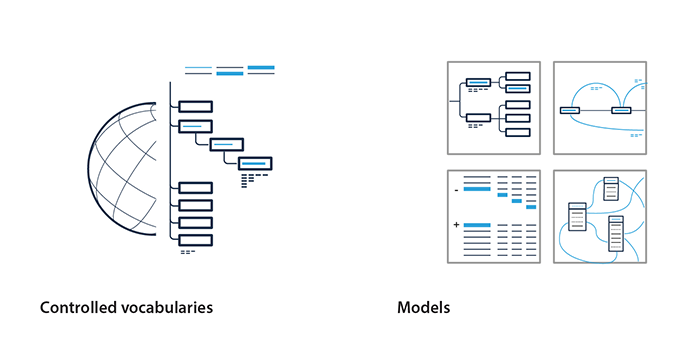
Controlled vocabularies are used to describe data in a consistent way. They are standardised and organised arrangements of words and phrases presented as alphabetical lists of terms, or as thesauri and taxonomies with a hierarchical structure. The use of broader and narrower relations defines the hierarchy and offers more flexibility in using the terms inside those vocabularies.
Data models help to organise elements of data and specify the connections between them. There are multiple types of data models: ontologies are primal in the creation or conceptualisation of controlled vocabularies; schemas can be used for the validation of documents and other data models can be derived from them; and application profiles define how given vocabularies will be used for subsequent IT purposes.
Producing linked open data
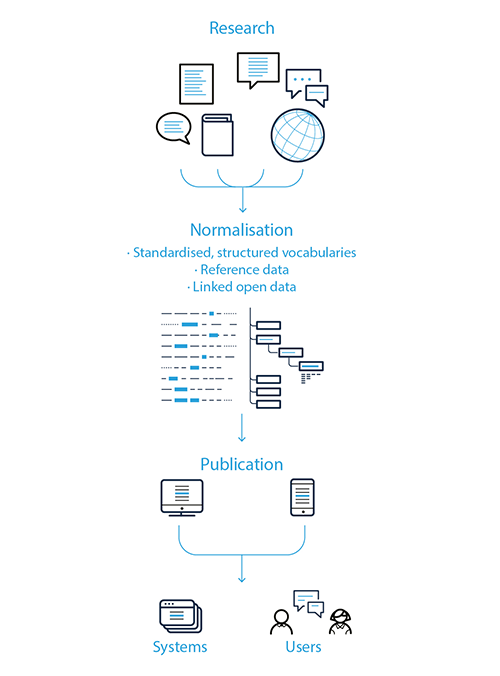
The vocabularies maintained by the Publications Office are LOD-ready. This means that they are open and connected between themselves and with outside resources. How is this achieved? The process of developing the vocabularies consists of three stages: research, normalisation and publication.
-
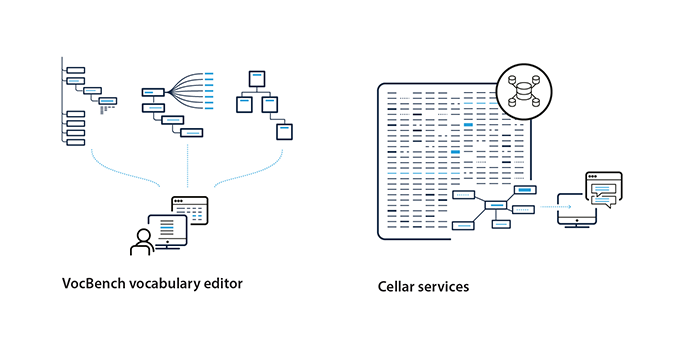
Research and preparation. Once the need for a new vocabulary or term is identified, data is collected and loaded into a semantic editorial platform (VocBench) that provides the necessary functions to develop the vocabulary into a proper LOD dataset.
-
Normalisation. This includes editing, adding standardised properties and validation of the data. The properties added here make the dataset LOD-compliant (e.g. uniform resource identifiers or URIs, language versions for the labels, links to internal and external datasets). The base structure for this development is the core Simple Knowledge Organization System model.
-
Publication. This includes a range of activities, including assessing whether there is a negative effect on connected resources or systems, conversion to different distribution formats, adding the necessary metadata to ensure compliance with LOD principles and the creation of a release package.
The release package is loaded in the CELLAR triple store, a semantic repository built by the Publications Office. It is a massive infrastructure service that includes large amounts of legal content, EU publications and reference datasets. The information is stored in accordance with the Publications Office’s common data model.
Published packages are presented on the EU Vocabularies website in different formats. For example, in RDF – an openly accessible format that can be identified by persistent URIs.
The published datasets and each individual term inside them are accessible through the website and on the dedicated SPARQL endpoint of the semantic triple store.
The last step to make datasets fully LOD-compliant is to make them available on larger platforms like data.europa.eu, so that interested re-users can find the data.
Why use linked open data for EU reference data?
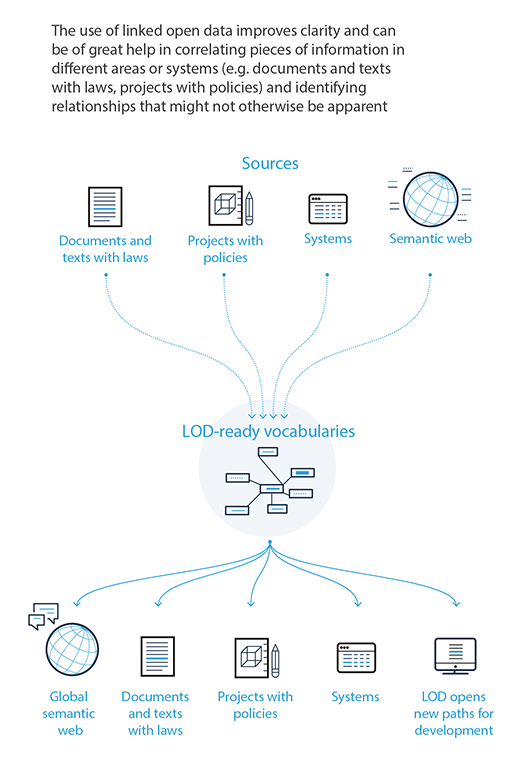
The goal of the vocabularies managed by the Publications Office is to connect systems and help those systems and their users refer to the same concepts, thus eliminating confusion and language barriers. The LOD approach is a step forward in that direction.
Using LOD for EU reference data allows to:
-
build relations between entities, connecting legislative acts, projects, initiatives, follow-up documents, activities and results;
-
organise documents in categories that are independent of language, institution and specificity of the domain;
-
benefit from enriched data due to the connections developed between vocabularies.
Why use EU reference data in your project?
Reusing the numerous controlled vocabularies and data models maintained and disseminated by the Publications Office can support projects that involve data, systems and/or human interactions. The resources are free, easy to use and can help save time and effort.
Furthermore, reusing these assets supports interoperability and streamlines efforts towards harmonisation and a better use of existing resources. As such, it eases the connection with other systems in the future, opening new paths for development.
Useful links
CELLAR: The semantic repository of the Publications Office
Graphics used in this article (available for reuse under CC-BY-4.0)